Python内置模块collections解析
python的collections模块提供了非常多方便的操作,例如
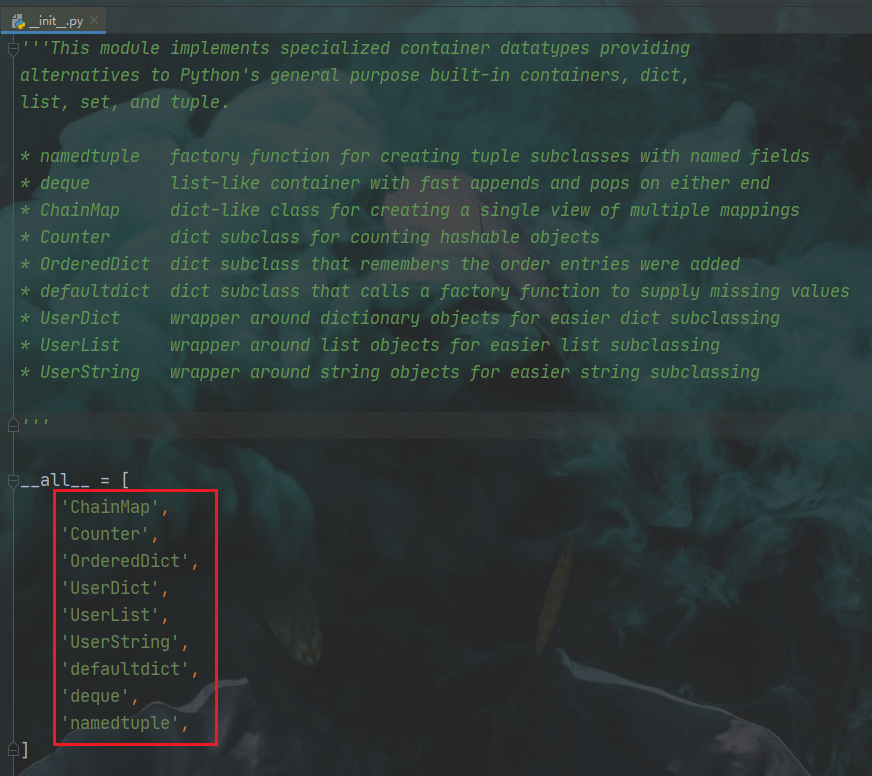
- Counter
- defaultdict()
- OrderDict()
- deque
- 双端队列
- namedtuple()
下面将逐个介绍每一个具体类的用法
Counter类
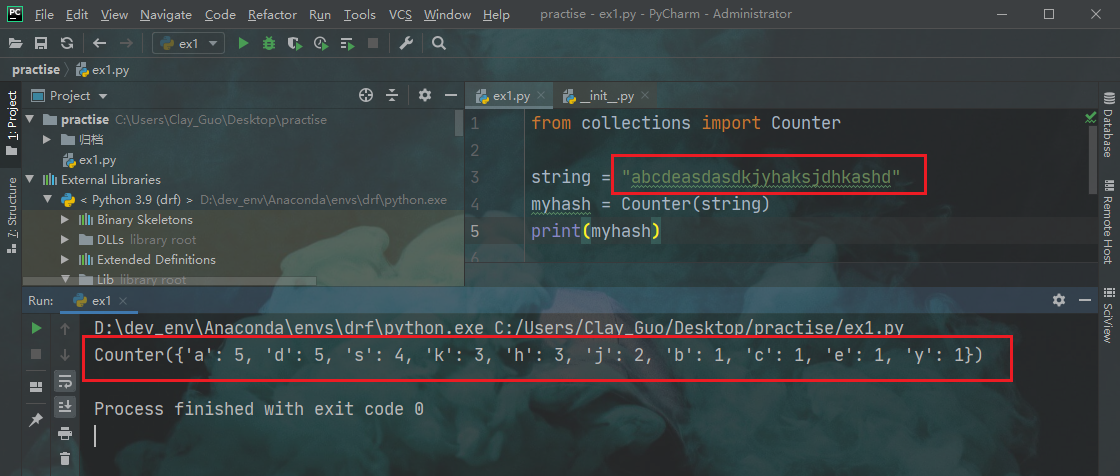
该类可以快速的进行统计,例如给定一个字符串之后,可以统计每个字符出现的次数,当然只要是可迭代【可哈希】的数据都是可以传给Counter中的,例如list,tuple等
1 | from collections import Counter |
该类中提供了几个方法可以使用
most_common()- 可以将字典中的元素按照出现次数组成一个元素,再按照出现次数从大到小排列成一个列表
- 例如:[(‘a’, 5), (‘d’, 5), (‘s’, 4), (‘k’, 3), (‘h’, 3), (‘j’, 2), (‘b’, 1), (‘c’, 1), (‘e’, 1), (‘y’, 1)]
element()- 该方法会返回一个迭代器,其中包含元素的重复次数,如果这个元素出现次数为0,则不会返回该元素,可以作为字符串对其进行处理
1 | my = Counter("123123asdasdas") |
defaultdict类
普通的字典在使用的时候,如果键不存在则会报错KeyError,这一点很影响使用体验,当然也可以每次都采用dic.get(key, defaultValue)的方式去获取值。这时就可以使用defaultdic来创建一个具有默认值的字典,这里的类型可以是整型、浮点型、列表、元祖、集合、字典等。
| 类型 | 初始值 |
|---|---|
| int | 0 |
| float | 0.0 |
| list | [] |
| tuple | () |
| set | set() |
| dict | {} |
1 | from collections import defaultdict |
OrderDict
OrderDict是一个可以按照元素添加顺序来存储键值对的字典类型,可以确保元素的顺序性。除了拥有普通字典的所有的操作以外,多了个顺序性。
底层采用的是双向链表,可以解决LRU算法的问题
1 | from collections import OrderedDict |
可以确保元素的打印顺序
其中有几个实用的方法:
- popitem(last=True)
- 该方法会移除字典最后一个元素,可以接收一个参数,如果为空默认为True移除最后一个元素,如果为False则移除第一个元素。
- move_to_end(key, last=True)
- 该方法会将指定key位置的元素移动到字典的最后【默认情况】,如果last为False则移动到最开头位置。
1 | from collections import OrderedDict |
deque
作为一个双端队列,此部分可以参考【二叉树总结】
实现树的层次遍历,使用popleft()方法可以提升效率。