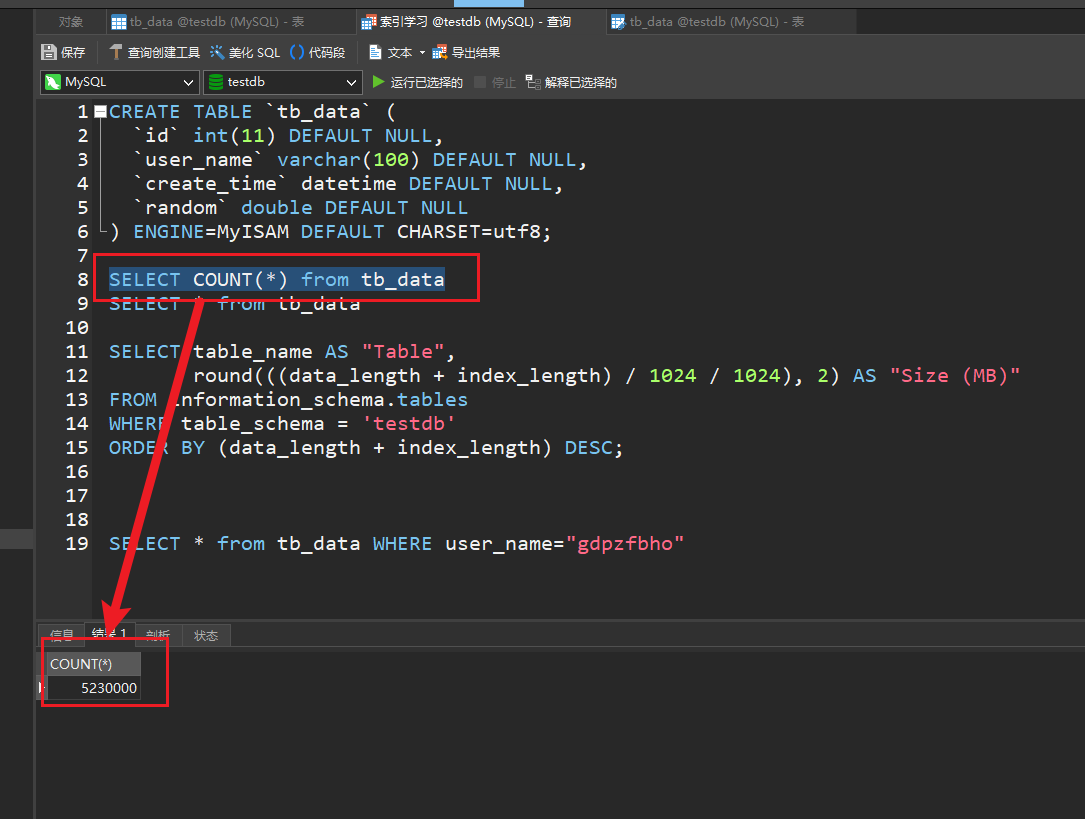
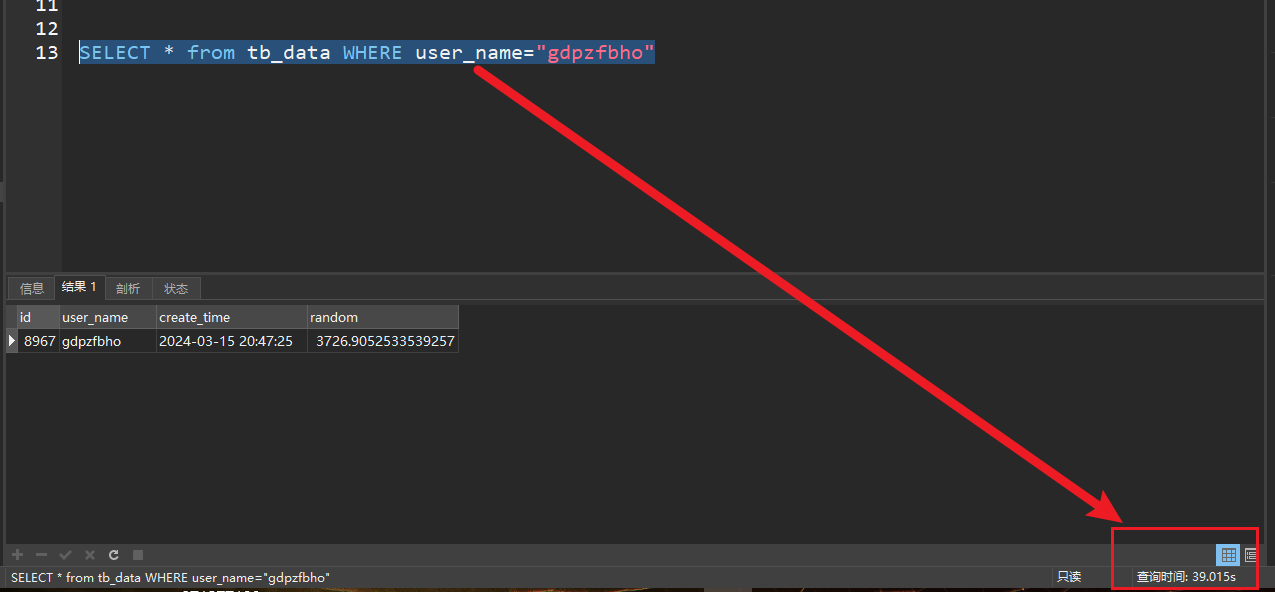
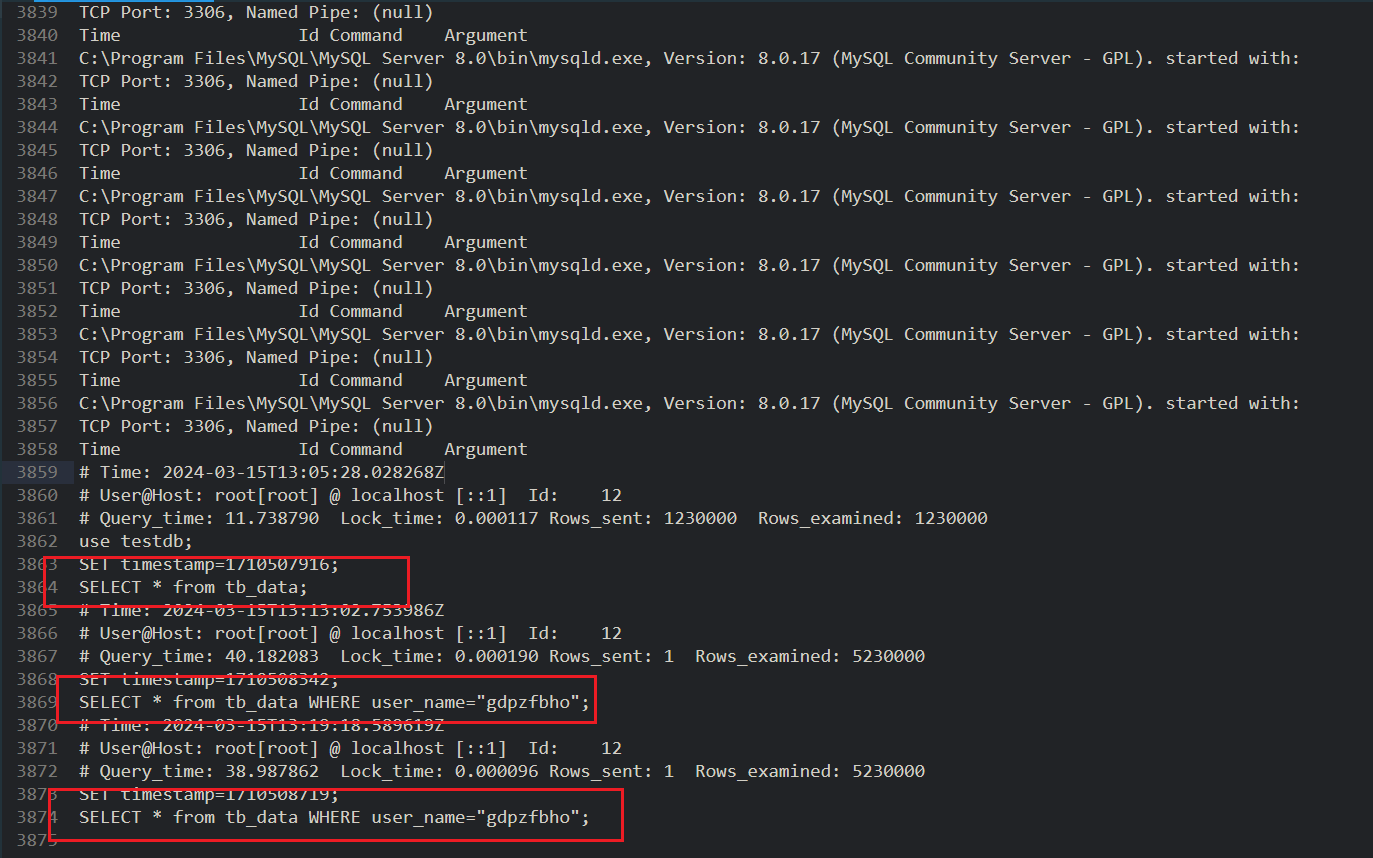
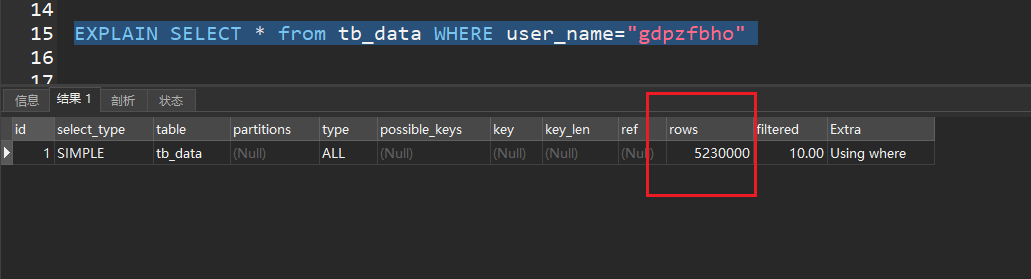
publicstatic String randomStr(int size){ // Define an empty string String result = ""; for (int i = 0; i < size; ++i) { // Generate an int type integer between 97 ~ 122 int intVal = (int) (Math.random() * 26 + 97); // Force conversion (char) intVal Convert the corresponding value to the corresponding character, and splicing the characters result = result + (char) intVal; } // Output string return result; }
publicstaticvoidinsert(int insertNum){ // open time Long begin = System.currentTimeMillis(); System.out.println("Start Inserting Data..."); // sql prefix String prefix = "INSERT INTO tb_data (id, user_name, create_time, random) VALUES ";
try { // save the sql suffix StringBuffer suffix = new StringBuffer(); // Set the transaction to non-automatic commit conn.setAutoCommit(false); PreparedStatement pst = conn.prepareStatement(""); for (int i = 1; i <= insertNum; i++) { // Build sql suffix suffix.append("(" + i + ",'" + randomStr(8) + "', SYSDATE(), " + i * Math.random() + "),"); } // Build a complete sql String sql = prefix + suffix.substring(0, suffix.length() - 1); // Add execution sql pst.addBatch(sql); // perform the operation pst.executeBatch(); // commit the transaction conn.commit();
// close the connection pst.close(); } catch (SQLException e) { e.printStackTrace(); } // End Time Long end = System.currentTimeMillis(); System.out.println("insert" + insertNum + " data data is completed!"); System.out.println("Time-consuming : " + (end - begin) / 1000 + "seconds"); }