Redis基础
NoSQL
认识redis
redis
Remote Dictionary Server 远程词典服务器
特征:
- 键值型,value支持多种不同数据结构
- 单线程,每个命令具有原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)
- 支持数据的持久化(定期将数据持久化到硬盘中)
- 支持主从集群、分片集群
- 支持多语言客户端
redis6.0开始的时候是网络请求部分多线程,其余的依旧是单线程
Redis命令
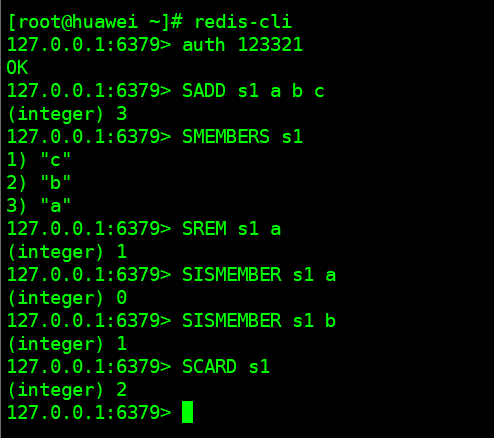
redis-cli -a 这个命令会调出控制台
redis-cli 进入到控制台的话,可以进入控制台,但是需要注意的是,如果设置了密码此时会提示你没有进行任何授权,需要进行授权
auth 123321
如果没有用户名直接auth + 密码即可
redis 常见命令
Redis常见数据结构
基本数据类型
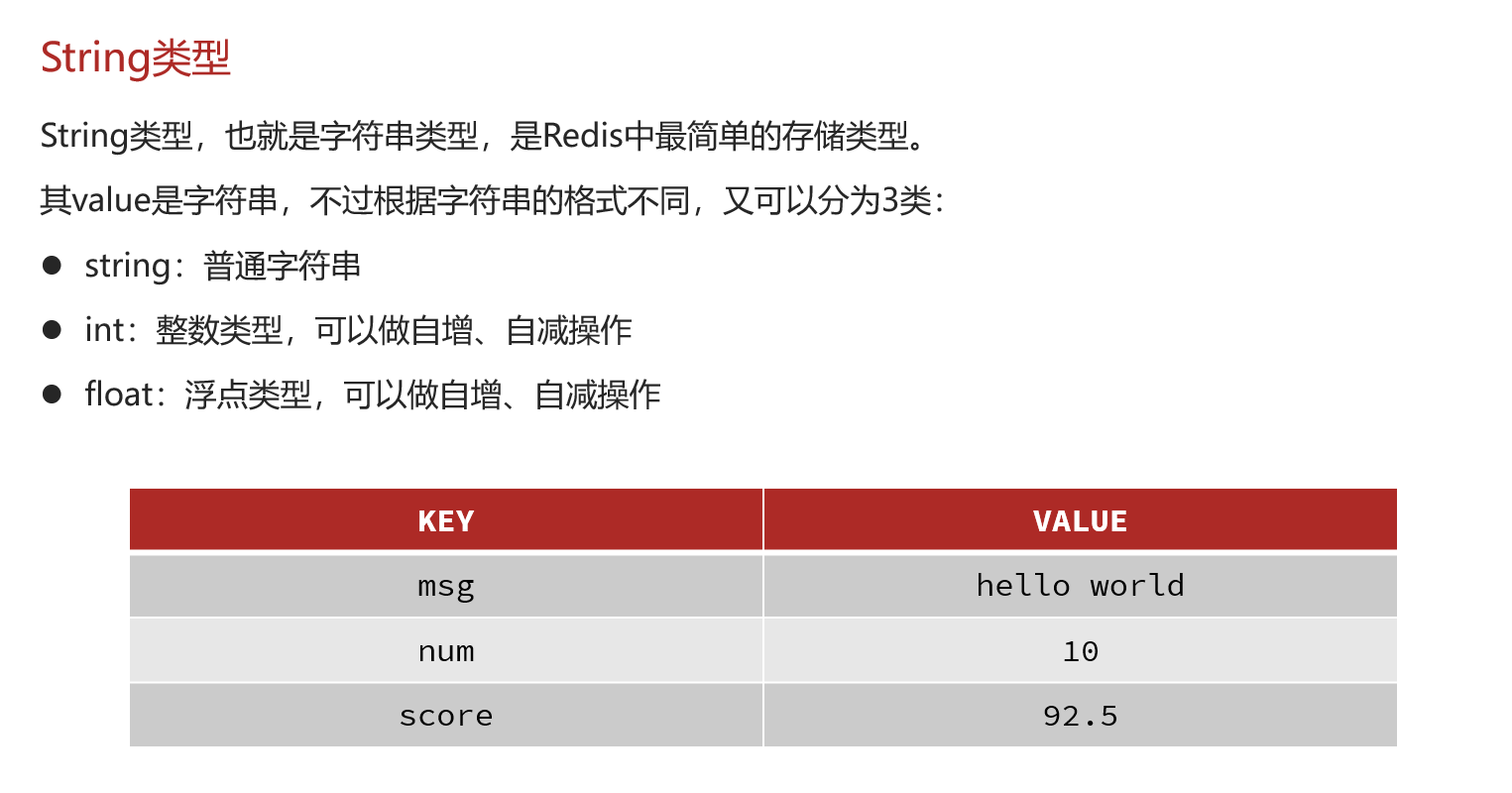
String类型
Hash类型
List类型
Set类型
SortedSet类型(ZSet)
特殊类型

Redis通用命令
通用命令是不分数据类型的,都可以使用的命令,常见的有:
KEYS:查看符合模板的所有key,不建议在生产环境中使用,会阻塞所有的请求DEL:删除一个指定的keyEXISTS:判断key是否存在EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除TTL:查看一个key的剩余有效期
如果一个key查询的有效期是-1,表示该key没有设置有效时间,即==永久有效==
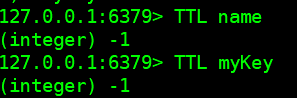
如果查询的有效期是-2,则表示该key已经已经到期了
String类型
底层都是以字节数组的形式去存储的,包括图片,最大的上限是512M
String的常见命令
String的常见命令有:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
Redis中没有MySQL中的表,如何区分不同类型的key?
例如需要存储用户、商品信息到redis,有一个用户id是1,商品id也是1怎么办?》
key的结构
Redis的key允许有多个单词构成层级结构,多个单词之间使用:隔开,格式如下:
项目名:业务名:类型:ID

字符串类型的三种格式:
- 字符型
- int
- float
值的类型是一个字符串
keys匹配
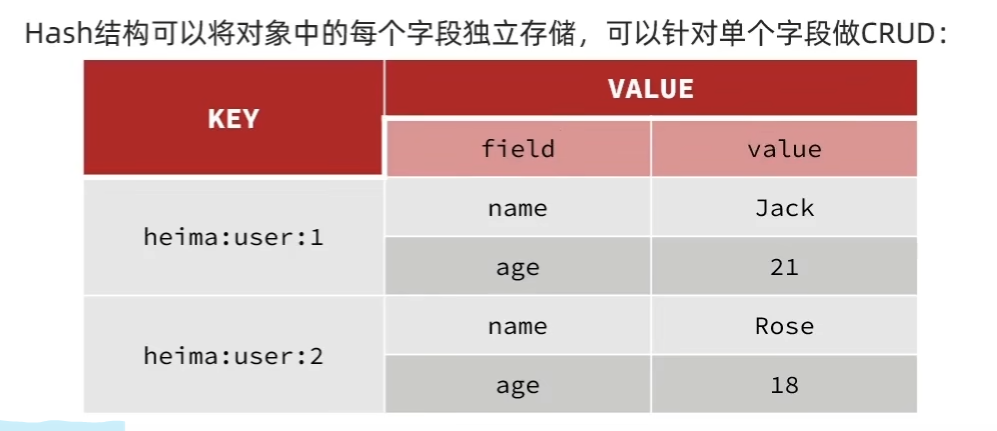
hash类型
String结构中,值如果是json对象,需要修改的话,只能将整个字符串全部修改,这样的方式不方便
但是在hash结构中,可以将每个字段独立存储,可以针对单个字段进行CRUD
hash类型的常见命令
相较于String类型而言,就是在其前面加上H即可
类似于java中的map
值的类型是一个哈希表
List类型
值的类型是一个list集合,底层可以看做是一个双向链表,支持正向检索和反向检索
特点:
- 有序
- 元素可以重复
- 插入和删除快(同链表)
- 查询速度一般
如何利用list模拟一个栈?
如何利用list模拟一个队列?
如何利用list模拟一个阻塞队列?
- 出口和入口在不同边
- 出队时采用BLPOP和BRPOP
Set类型
Redis的set类型与Java中的HashSet类似
特点:
- 无序
- 元素不可重复
- 查找快
- 支持交集、并集、差集等功能
Set类型的常见命令
- SADD key member:向set中添加一个或多个元素
- SREM key member:移除set中的指定元素
- SCARD key:返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中所有元素
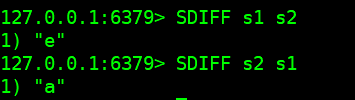
- SINTER key1 key2:求key1与key2的交集
- SUNION key1 key2:返回多个集合的并集
- SDIFF key1 key2:返回多个集合的差集
SortedSet类型
这是一个可排序的set集合,与Java的TreeSet有些类似,但底层数据结构差别很大。
SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素进行排序,底层的实现是基于一个跳表+hash表
特点:
- 可排序
- 元素不重复
- 查询速度快
用途
用于实现排行榜这样的功能
常见命令
- ZREVRANK key member:获取降序排名
- ZRANK key member:获取排名
Redis的Java客户端
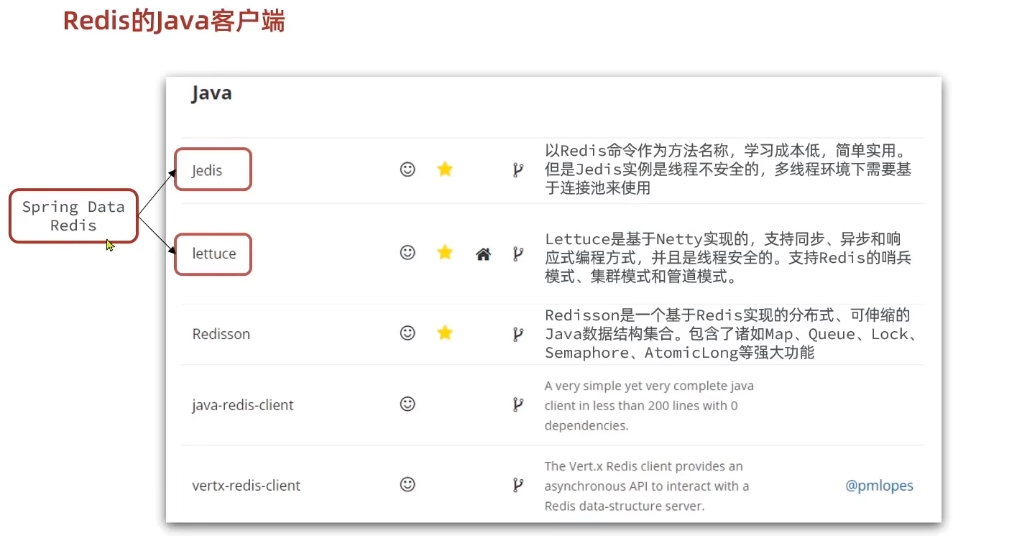
Jedis
JedisTest.java
1 | package com.heima.test; |
静态初始化块,在类加载时执行,用于初始化静态成员变量或执行一些静态操作。
JedisConnectionFactory.java
1 | package com.heima; |
单例模式
JedisConnectionFactory 类中的 jedisPool 属性被声明为 static,并在静态初始化块中初始化。这样做确保了在整个应用程序生命周期中只有一个 Jedis 连接池实例。
工厂模式
类中的getJedis()方法充当了工厂方法,用于创建Jedis对象。它封装了Jedis连接池的创建和配置细节,并提供了一个统一的接口来获取Jedis对象。
Spring Data Redis
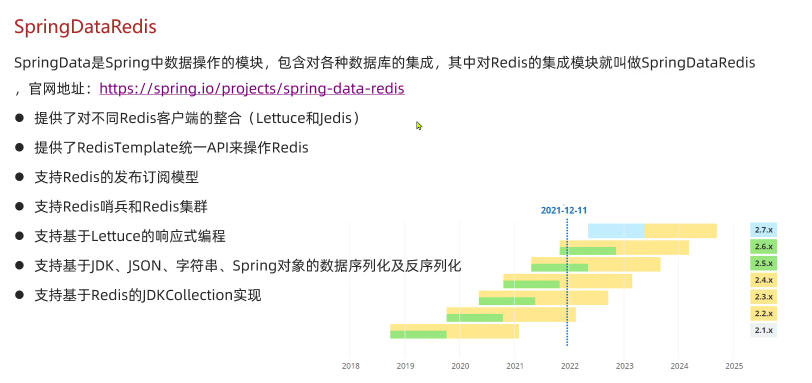
使用Spring Data Redis步骤
- 引入依赖
- 配置Redis
- 注入RedisTemplate
- 编写测试
序列化的问题:
RedisTemplate可以接收任意Object作为值写入Redis,只不过写入前会把Object序列化为字节形式,默认采用JDK序列化。
缺点:
- 可读性差
- 内存占用较大
redisTemplate

redisTemplate操作hash
1 |
|
实战阶段
课程介绍
短信登录
- Redis的共享session应用
商户查询缓存
- 企业缓存使用技巧
- 缓存雪崩、穿透等问题解决
达人探店
- 基于List的点赞列表
- 基于SortedSet的点赞排行榜
优惠券秒杀
- Redis的计数器
- Lua脚本
- Redis分布式锁
- Redis的三种消息队列
好友关注
- 基于Set集合的关注、取关、共同关注
- 消息推送
附近的商户
- GeoHash的应用(根据地理坐标获取数据)
用户签到
- BitMap数据统计功能
UV统计
- HyperLogLog的统计功能
短信登录
导入黑马点评项目
导入sql文件,其中包括
- tb_user:用户表
- tb_user_info:用户详情表
- tb_shop:商户信息表
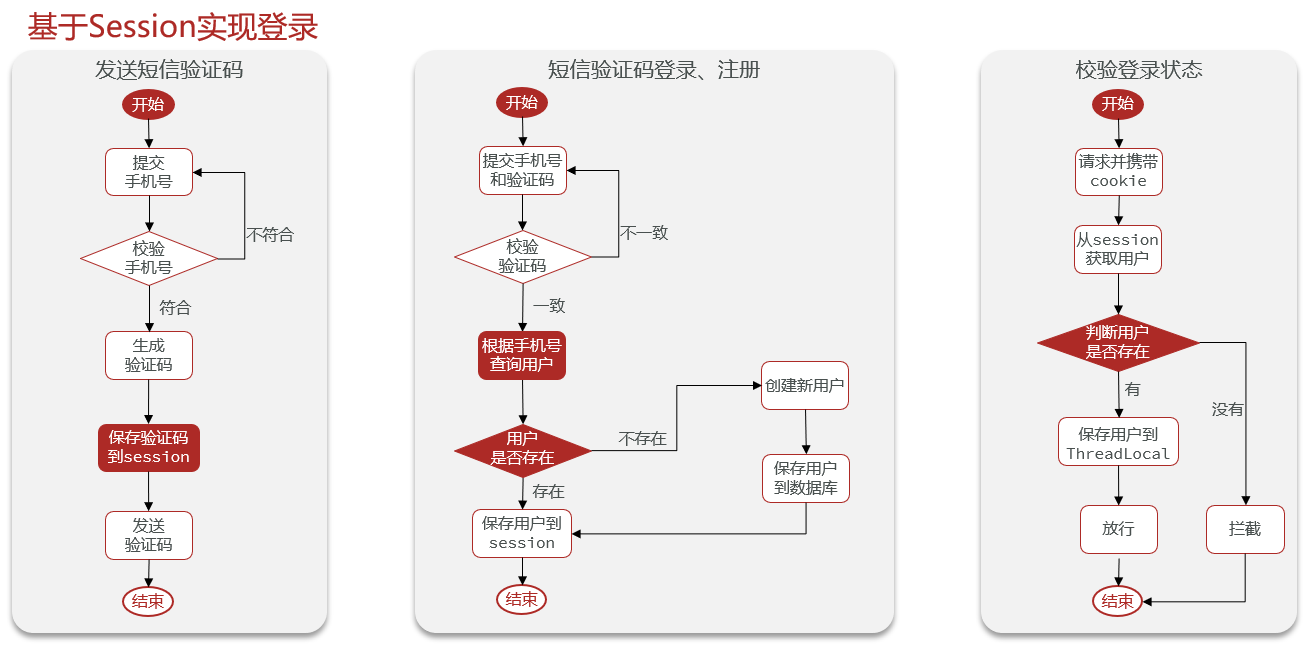
基于Session实现登录
集群的session共享问题
基于Redis实现共享session登录
发送验证码的逻辑
发送短信验证码
- 校验:手机号是否符合规定
短信验证码登录、注册
- 校验:手机号对应的用户是否存储在数据库中
校验登录状态
- 校验:
发送短信验证码
UserController.java
1 | /** |
IUserService.java
1 | Result sendCode(String phone, HttpSession session); |
UserServiceImpl.java
1 |
|
登录
拦截器
SpringMVC中提供了拦截器
集群的session共享问题
sessionStorage
商户缓存查询
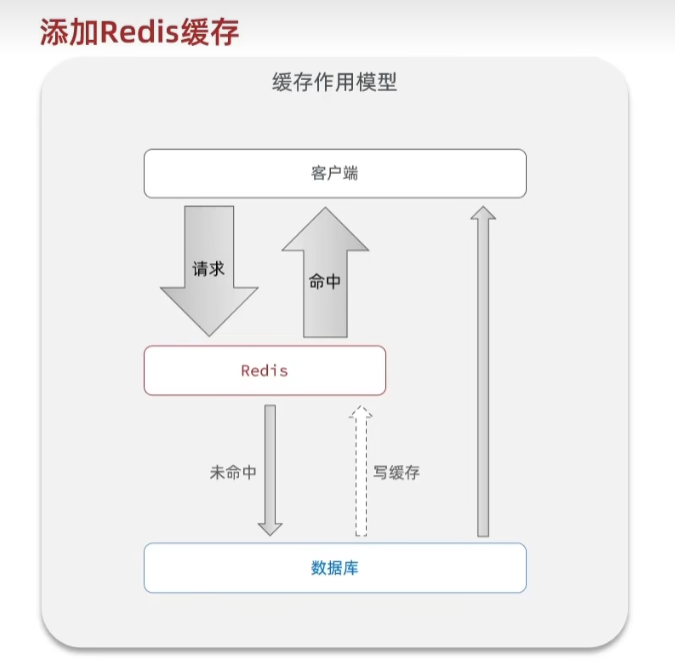
什么是缓存?
缓存是数据交换的缓冲区,是存储数据的临时地方,一般读写性能高
缓存的作用
- 降低后端负载,避免在后端频繁的查询数据库
- 降低读写效率,降低系响应时间
成本:
- 数据一致性
- 代码维护成本
- 运维成本
添加Redis缓存
根据ID查询商品缓存的流程
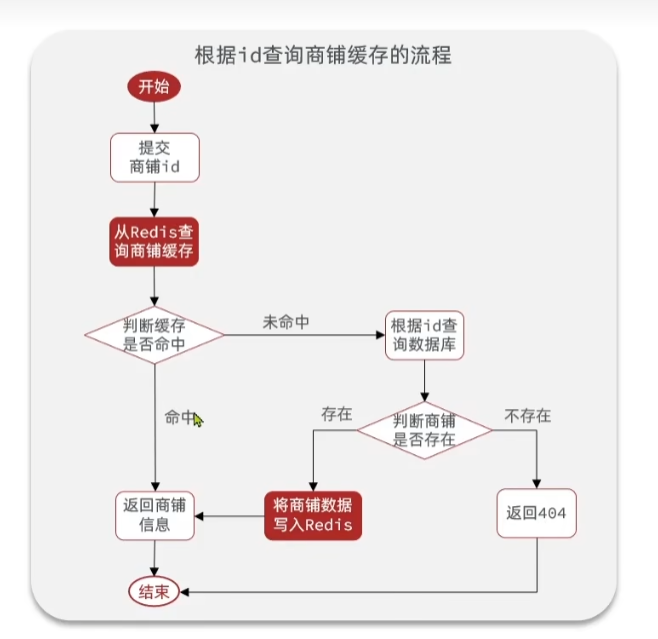
原本的代码中是直接走数据库中进行查询的
1 | /** |
其中getById是使用mybatis直接从数据库中进行查询,在IService中有
1 | default T getById(Serializable id) { |
现在的代码中,首先会去缓存中查询,如果不存在才会去MySQL中查询
缓存更新策略
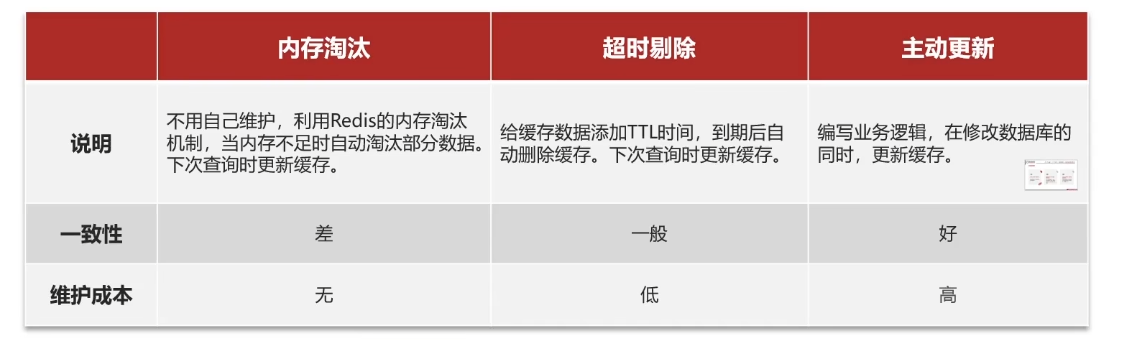
业务场景:
- 低一致性需求:使用Redis自带的内存淘汰机制。例如店铺类型的查询缓存
- 高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存。
主动更新策略
Cache Aside Pattern:由缓存的调用者,在更新数据库的同时更新缓存
Read/Write Through Pattern:缓存和数据库整合为一个服务,由服务来维护一致性。调用者调用该服务,无需关心缓存一致性问题。
Write Behind Caching Pattern:调用者只操作缓存,由其他线程异步的将缓存数据持久化到数据库,保证最终一致。

缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
缓存空对象
- 思路:对于不存在的数据也在Redis建立缓存,值为空并设置一个较短的TTL时间
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致问题
布隆过滤
- 在Redis和MySQL中间加上布隆过滤算法,在请求进入Redis之前先判断是否存在,如果不存在则直接拒接请求。
- 优点:占用内存少
- 缺点:实现复杂;可能存在误判的情况,即布隆过滤算法说MySQL中有,但是实际并没有该数据的情况
店铺如果不存在,将空值写入Redis
命中时,如果为空值,也需要返回不存在
缓存雪崩
缓存雪崩是同一时段大量的缓存key同时失效或者Redis服务器宕机,导致大量的请求到达数据库,带来巨大的压力。
解决方案:
- 给不同的key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数请求访问会在瞬间给数据库带来巨大的冲击。
热点Key + 缓存重建时间比较长
- 缓存重建业务较为复杂:
- 涉及到多表查询或者表关联运算,业务耗时比较长,可能有数百毫秒
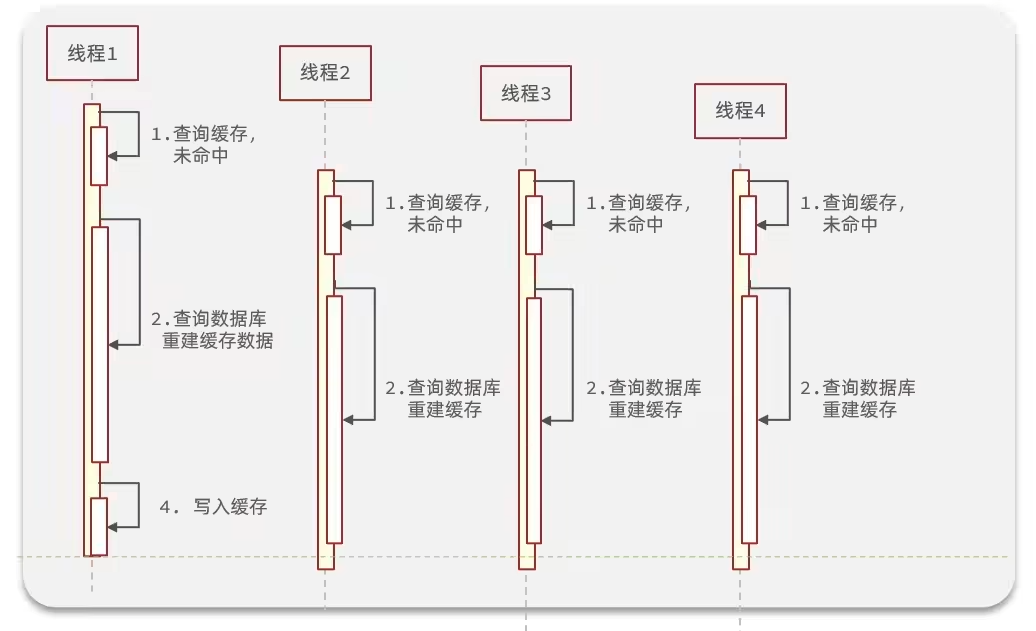
缓存雪崩是由于大量key过期导致的结果,缓存击穿是由于部分的key(通常是一些热点key)突然失效的结果。
解决缓存击穿的方法
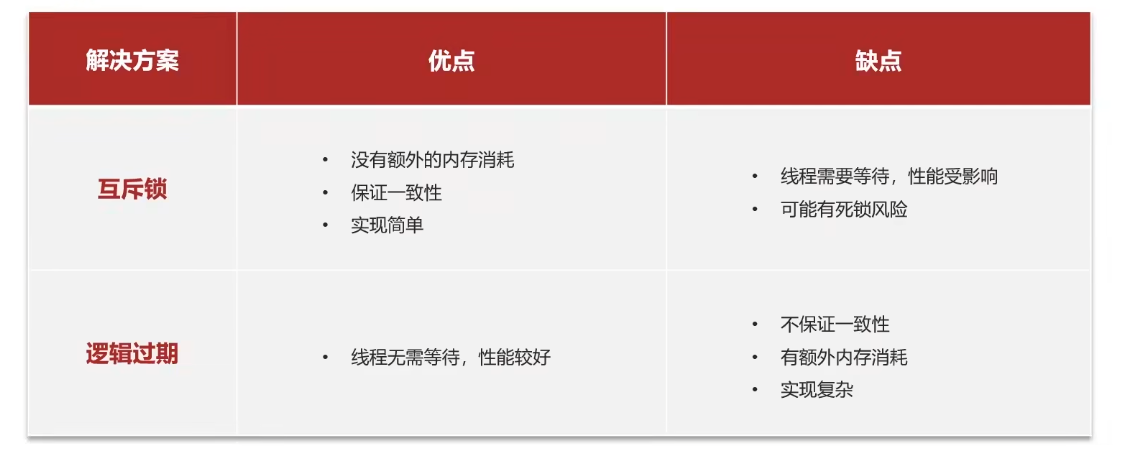
互斥锁
缓存重建的过程中加锁,确保重建过程只有一个线程执行,其他线程阻塞
优点:
- 实现简单
缺点:
- 等待导致性能的下降
- 有死锁的风险
逻辑过期
- 不给key设置ttl,在其value中加上一个字段
expire表示过期时间(时间戳) - 热点key缓存用户过期,而是设置一个逻辑过期时间,查询到数据时通过对逻辑过期时间进行判断,决定是否需要重建缓存
- 重建缓存也通过互斥锁保证单线程执行
- 重建缓存利用独立线程异步执行
- 其他线程无需等待,查询到旧数据即可。
- 优点:
- 线程无需等待,性能较好
- 缺点
- 不能保证数据一致性
- 有额外的内存消耗
- 实现复杂
- 不给key设置ttl,在其value中加上一个字段
互斥锁解决缓存击穿
2024.3.2
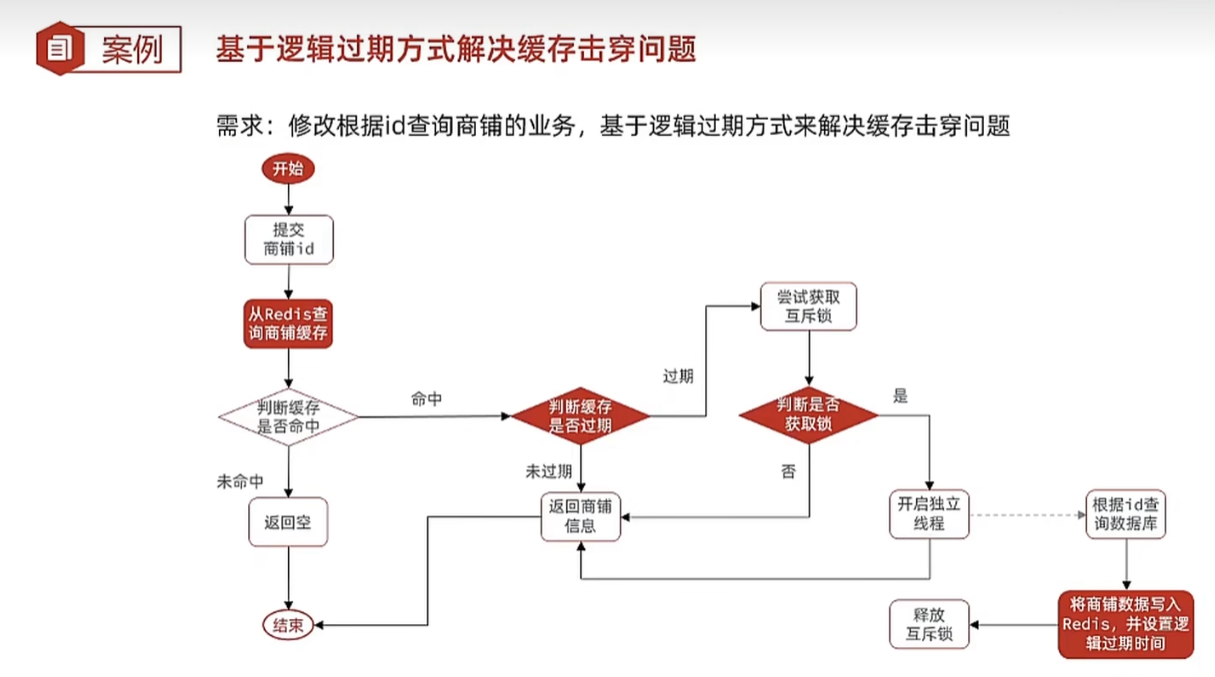
逻辑过期解决缓存击穿
2024/3/3
需求:修改根据id查询商铺的业务,基于逻辑过期方式来解决缓存击穿问题
缓存工具封装
- 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
- 方法2:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用户处理缓存击穿问题
- 方法3:根据指定的key查询缓存,并反序列化为指定类型,利用缓存控制的方法解决缓存穿透问题
- 方法4:根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期时间解决缓存击穿问题。
优惠券秒杀
订单表如果使用数据库自增ID就会存在一些问题:
- ID规律太明显
- 首单表数据量的限制
- 订单需要确保唯一性
全局ID生成器
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特征:
唯一性(订单ID必须唯一)
高可用
- 集群方案、主从方案、哨兵方案
高性能
- 速度足够快
递增性
- 单调递增性,有利于创建数据库索引
安全性
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其他信息。
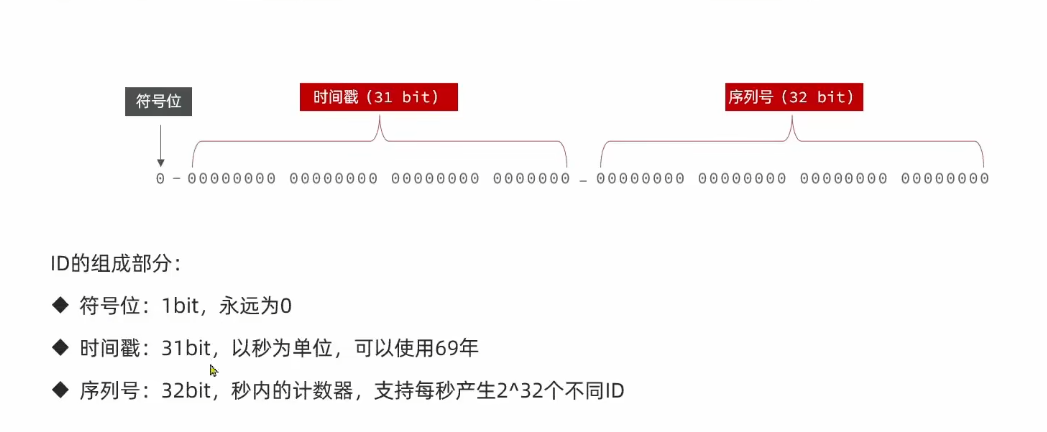
8个字节,64个比特位



