
程序员面试宝典
作者 Clay_Guo
零、前言
本文档是基于本人在2020秋招以及2021秋招过程中的面试经验,希望可以帮助到有需要的人进行面试的准备,当然由于本人能力有限,文档部分如果不正确的地方也请不领赐教。联系邮箱:guoyinzhi@foxmail.com
一、自我介绍
自我介绍保持在三分钟左右即可,简洁明了,让面试官知道你自己的长处在哪,可以适当的说一些项目经历。
运维开发(SRE)工程师自我介绍
中文
面试官你好,我叫xxx,我的本科的专业是软件工程,在校期间我学过的课程有C语言,数据结构,操作系统,计算机网络,数据库、设计模式、java 、java-web,C#等课程。我个人大二大三课余时间学习过系统(主要是Red Hat操作系统)和网络相关的知识,然后考了RHCE的证书。平时的话也会倒腾自己在阿里云上租的一台云服务器(搭建博客、图床、FTP服务器等、在线Jupyter notebook)。本身的专业是开发出生,也了解一些系统网络相关知识,加上之前有一位老师给自己引路,因此我个人对于DEVOPS这个方向比较感兴趣,因此投递了贵公司的运维开发工程师岗位。
英文版本
Hello Interviewer, my name is xxx. My major is Software Engineering. My undergraduate courses include C, data structures, operating systems, computer networks, databases, design patterns, java, javaweb etc. I have studied systems and network after school in my sophomore and junior years. Mainly in Red Hat’s RHCE and Cisco’s Routing and switch direction. I personally build some applications on my own cloud server, such as personal blogs, image beds, FTP servers, etc. I am interested in Python, so I am applying for the position of Software Development Engineer in your company.
Golang后端开发工程师自我介绍
中文
面试官你好,我叫xxx,我的本科专业是软件工程,在校期间我学过的一些课程有C语言,数据结构、操作系统、计算机网络、数据库、设计模式、java、java web、面向对象程序设计等课程。我个人在大二大三课余的时间里面,学习过系统和网络方向的知识,系统主要是红帽的RedHat操作系统,网络主要是思科的RS路由交换方向的内容,之后也考取了一个RHCE的证书。平时呢我也会去在我租的阿里云的服务器上部署一些个人的小应用,比如说个人博客、图床、FTP服务器、jupyter notebook等。之前在学习docker的时候有了解到云原生的相关知识,然后也接触到了Go语言,自己对于这个方向也是比较感兴趣的,因此投递的了贵公司的Golang后端开发工程师的岗位。
英文版本
二、项目介绍
项目部分很重要,不要说自己没做过的,有的对你写的项目技术点很熟悉的面试官是会问你到你绝望的,另外往往面试官也会问你在项目中所遇到的一些问题来,这点最好先提前准备下,做到有备无患。
2.1 RoboCup3D仿真机器人的设计
在仿真Simspark环境中,设计机器人的各类动作,从而让机器人可以在球场的环境中进行11v11的比赛。
我主要负责的是对机器人步态以及射门的研究以及机器人高层逻辑决策的设计
利用Chainer框架中的DDPG算法对我们的Nao机器人进行优化。
功能介绍:在Ubuntu下的3D仿真环境中,设计足球机器人来实现与人类足球运动一样的11v11的竞赛。主要负责双足机器人步态、射门以及机器人逻辑决策层的研究。利用Chainer框架中DDPG算法对机器人的步态进行优化,参加2019年RoboCup机器人世界杯中国赛并获得3D仿真组二等奖。
2.2 河海大学优必选科技冬令营
利用优必选科技的Yanshee机器人进行二次开发,我们主要做的就是设计语音模块的调用,舞蹈动作的编排
功能介绍: 在树莓派下,用Python进行基于优必选科技 Yanshee 机器人的二次开发,完成了人脸识别、语音识别等模块的开发,利用Python爬虫从中国天气网爬取实时天气情况,由机器人汇报,设计编排机器人的舞蹈动作并利用 sockets编程来实现机器人协同跳舞,在最终的团队结项考核中获得银奖。
2.3 智慧校园项目
项目地址:*https://github.com/GuoXianSen/IntelligentCampus*
功能介绍:微信小程序端作为前台,模块包括校园资讯、校园商城、商品管理、用户管理、教务信息、健康码管理等,通过管理后台对小程序端的校园商城、校园资讯数据进行管理。负责整个项目的整体规划设计、原型设计、数据库设计到最终的测试以及上线部署。本人主要进行后端开发,包括利用Layui框架编写管理后台,面向接口编程,供前端调用;利用Python进行教务信息(课表和成绩)爬取,利用flask做成接口供前端页面使用。
2.4 个人博客搭建
目前的个人博客地址:*https://guoxiansen.github.io*
三、技术环节
3.1 数据结构与算法
数据结构与算法部分推荐两本书《大话数据结构》《剑指offer》以及刷题网站LeetCode,刷力扣的热题100
3.1.1 全排列问题
例如abc进行全排列的话
使用到递归算法
3.1.2 查找算法
- 折半查找
3.1.3 排序算法
https://www.cnblogs.com/onepixel/articles/7674659.html
冒泡算法
冒泡算法就是从当前的一个数字和后面的数字依次进行比较,从大到小排序或者从小到大排序
如果比后面的数字小就交换,
时间复杂度是Ο(n2)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main(){
int i,j;
int a[] = {1,3,5,7,9,0,2,4,6,8,};
int tmp;
// 外循环表示比较的轮数,而内循环才表示具体在比较的东西
for(i = 0; i < 9; i++){
for(j=0; j< 9-i; j++){
if(a[j]>a[j+1]) {
tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
}
}
}
for(i=0; i<10; i++){
printf("%d,",a[i]);
}
return 0;
}选择排序
首先在未排序的序列中找到最大(小)的元素,放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最大(小)的元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素全部排序完毕。
他的时间复杂度是Ο(n2)、
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
int main(){
int i,j;
int a[] = {1,3,5,7,9,0,2,4,6,8,};
int tmp;
int min;
for(i=0; i < 9; i++){
min = i;
for(j = i+1; j < 10; j++){
if(a[min]>a[j])
min = j;
}
tmp = a[min];
a[min] = a[i];
a[i] = tmp;
}
for(i=0; i<10; i++){
printf("%d,",a[i]);
}
return 0;
}插入排序
希尔排序
快速排序
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
堆排序
归并排序
记数排序
基数排序







3.1.4 如何检测链表是否成环
可以设置两个指针,一个走的慢一点,一个走的快一点,如果两个相遇,那么就说明链表成环了。
3.1.5 解释一下什么是哈希表
3.2 Python
Python中有哪些Coding Style
列表中间空格
爬虫的爬与反爬是如何实现的
爬虫
- urllib
- requests
- xpath
- bs4
- re
反爬
- 加上herder
- 使用代理池技术
正则表达式
用Python写过什么程序?
即时通讯软件
https://www.runoob.com/python/python-socket.html
利用socket进行编程
利用Socket模块写了一个即时通信软件
Python爬虫接口
用flask写过一个爬虫程序的接口


Python中with方法你知道吗?
文件的打开方法
1 | with open ("./image.png","wb") as f: |
如何在函数内部修改全局变量?
使用全局变量
global
Python的数据结构有哪些?
注意各个数据结构的内置方法
列表 里面的一些方法
元组 元组不可变
字典
可以使用字典的key()方法或者value()方法来获得字典的全部键值
集合
可变对象和不可变对象的区别
什么情况下会考虑使用lambda函数
提升效率
对于一些临时性的,小巧的函数。
使用lambda函数更为轻巧,方便进行函数式编程
可以作为回调函数,传递给某些应用,比如消息处理对于一些功能复杂的函数,还是直接定义为好
Python中深拷贝和浅拷贝的区别是什么?
(1)
深拷贝是将对象本身复制给另一个对象。这意味着如果对对象的副本进行更改时不
会影响原对象。在 Python 中,我们使用 deepcopy()函数进行深拷贝.
(2)
浅拷贝是将对象的引用复制给另一个对象。因此,如果我们在副本中进行更改,则
会影响原对象。使用 copy()函数进行浅拷贝
Python中is和==的区别
is比较的是两个实例对象是不是完全相同,它们是不是同一个对象,占用的内存地址是否相同。莱布尼茨说过:“世界上没有两片完全相同的叶子”,这个is正是这样的比较,比较是不是同一片叶子(即比较的id是否相同,这id类似于人的身份证标识)。
==比较的是两个对象的内容是否相等,即内存地址可以不一样,内容一样就可以了。这里比较的并非是同一片叶子,可能叶子的种类或者脉络相同就可以了。默认会调用对象的 eq()方法。
Python闭包你知道吗?
在函数的内部定义了一个函数,并且这个函数用到了外面函数的变量,那么将这个函数和外面这个变量称作是闭包
闭包是一种保护私有变量的机制,在函数执行时形成私有的作用域,保护里面的私有变量不受外界干扰。
Python2和Python3的区别
Python2中print是语句,而Python3中print是函数
编码
Python2 的默认编码是 asscii,Python 3 默认采用了 UTF-8 作为默认编码
字符串
True和False
Python2中True和False是两个全局变量的名字,在数值上对应0和1,因此作为变量就可以指向其他对象。而Python3中,True和False是两个固定的对象, 不允许再被重新赋值。
迭代器
解释一下什么是装饰器
装饰器的概念
装饰器本只上是一个Python函数,它可以让函数在不进行任何代码改动的前提下增加额外的功能,装饰器的返回值也是一个函数对象
装饰器的用途
装饰器一般可以用来测试函数的运行效率
装饰器本质上是一个Python函数,它可以让其它函数不变动的情况下增加新的功能,装饰器的返回值也是以一个函数。它经常用于有切面需求的场景。比如:插入日志,性能测试,缓存,事务处理,权限校验等。有了装饰器我们就可以抽出大量与函数无关的雷同代码进行重用。
迭代器你知道吗?请解释下原理。
你常用模块有哪些
1 | import random |
你用过多线程嘛?具体是怎么使用的?
我在使用
Python是解释型语言还是编译型语言?
先说结论:Python是一门先编译后解释的语言
初学Python的时候,就听说Python是解释型语言,但是实际上并不是这样。
编译型语言
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了,最典型的例子就是C语言。
解释型语言
解释型语言就没有这个编译过程,而是在程序运行的时候,通过解释器对程序逐行做出解释,然后直接运行,最典型的例子是Ruby。
两种类型的优缺点
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
Python程序执行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当Python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当Python程序第二次运行时,首先程序会在硬盘中寻找对应的pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件:pyc文件其实是PyCodeObject的一种持久化保存方式。pyc文件的目的
回想上面我们在分析编译型语言和解释型语言的优缺点时,编译型语言的优点在于,我们可以在程序运行时不用解释,而直接利用已经翻译过的文件。也就是说,我们之所以要把py文件编译成pyc文件,最大的优点在于我们在运行程序时,不需要重新对该模块进行再次解释。
所以,需要编译成pyc文件的应该是那些可以重用的模块,这与我们在设计类时是一样的目的。所以Python的解释器认为:只有import进来的模块,才是需要被重用的模块。
这个时候也许有人会有疑问,我的test.py不是也需要运行吗,虽然不是一个模块,但是以后我每次运行也可以节省时间啊!
OK,我们从实际情况出发,思考一下我们在什么时候才可能运行python xxx.py文件:
- 执行测试时;
- 开启一个Web进程时;
- 执行一个脚本时。
我们来逐条分析,第一种情况就不多说了,这个时候哪怕所有的文件都没有pyc文件都是无所谓的。
第二种情况,试想一个web.py的程序,通常是这样执行的:
然后这个程序就类似于一个守护进程一样一直监视着8000端口,而一旦中断,只可能是程序被杀死或者其他的意外情况,那么你要做的是把整个Web服务重启,那么既然一直监视着,把PyCodeObject一直放在内存中就足够了,完全没有必要持久化到硬盘上。
再来看看最后一个情况,执行一个程序脚本,一个程序的主入口其实很类似于Web程序中的Controller,也就是说,他负责的应该是Model之间的调度,而不包含任何的主逻辑在内,只是负责把参数转来转去而已,那么如果做算法的同学可以知道,在一段算法脚本中,最容易改变的就是算法的各个参数,那么这个时候将它持久化成pyc文件就未免有些画蛇添足了。所以我们可以这样理解Python解释器的意图,Python解释器只是把我们可能重用到的模块持久化成pyc文件。
pyc文件的过期时间
说完了pyc文件,可能有人会想到,每次Python解释器都把模块给持久化成pyc文件,那么当我的模块发生改变的时候,是不是都要手动的把之前的pyc文件remove掉呢?当然Python的设计者是不会犯这样的错误的,这个过程其实取决于PyCodeObject是如何写入pyc文件中的。我们仔细看一下import模块的源码其实不难发现,它在写入pyc文件的时候,写了一个Long型变量,变量的内容则是文件的最近修改日期,同理,在pyc文件中,每次在载入之前都会检查一下py文件和pyc文件保存的最后修改日期,如果不一致则重新生成新的pyc文件。
总结
其实了解Python程序的执行过程对于大部分程序员来说意义都是不大的,那么真正有意义的是,我们可以从Python解释器的做法上学到一些处理问题的方式和方法:
- 在Python中判断是否生成pyc文件和我们在设计缓存系统时是一样的,我们可以仔细想想,到底什么是值得扔在缓存里面的,什么是不值得的。
- 在运行一个耗时的Python脚本时,我们如何能够做到稍微压榨一些程序的运行时间呢?就是将模块从主模块分开。(虽然往往这都不是瓶颈)
- 在设计一个软件系统时,重用和非重用的东西是不是也可以分开来对待,这是软件设计原则的重要部分。
- 在设计缓存系统(或者其他系统)时,我们如何来避免程序的过期,其实Python解释器为我们提供了一个特别常见而且有效的解决方案。

3.3 Go语言
3.4 Java方向
java集合类
集合类型主要有3种:set(集)、list(列表)和map(映射)。
HashSet LinkedHashSet TreeSet的主要使用情境
集合接口分为:Collection和Map,list、set实现了Collection接口
解释一下JVM虚拟机
1 |
简述一下Java中的垃圾回收机制
HashMap
3.5 运维方向
常见运维平台有哪些
腾讯蓝鲸
和其余各大厂商自行开发的运维平台
对DEVOPS和自动化运维开发的理解SRE思想
在我看来Devops是传统运维技术上的进阶分支,应该去学习这些新的技术去扩充自己,而不是担心会被取代。Devops很大程度上的代替了传统运维的手工操作,运维人员只需写好自动化运维脚本(需要学习和钻研,各公司业务需求不同脚本也不同,不能生搬硬套),利用自动化工具(zabbix,elk,ansible等)就可以实现自动监控自动告警,省去了很多人力。省去了很多不必要浪费的人力时间,但是更重要的是它做到了服务备用机制,对于公司而言,不可能时时刻刻都能提供正常有效的服务,有时候突发情况导致的服务终端是非常影响客户体验以及公司利益的,在突发情况下,及时发现以及紧急抢修维护必不可少,但突发情况下的服务继续我认为才是Devops真正的核心,两地三中心,三地五中心也是这个道理。
对运维的理解

持续集成/持续部署CI/CD
持续集成的基本思想是让一个自动化过程监测一个或多个源代码仓库是否有变更。当变更被推送到仓库时,它会监测到更改、下载副本、构建并运行任何相关的单元测试。
云计算和DEVOPS的关系
什么是云原生
云原生 是基于分布部署和统一运管的云端服务,以容器、微服务、DevOps等技术为基础建立的一套云技术产品体系。
分成云和原生
云是和本地相对的,传统的应用必须跑在本地服务器上,现在流行的应用都跑在云端,云包含了IaaS、PaaS和SaaS。
原生就是土生土长的意思,我们在开始设计应用的时候就考虑到应用将来是运行云环境里面的,要充分利用云资源的优点,比如️云服务的弹性和分布式优势。
微服务
微服务解决的是我们软件开发中一直追求的低耦合+高内聚,记得有一次我们系统的接口出了问题,结果影响了用户的前台操作,于是黎叔拍案而起,灵魂发问:“为啥这两个会互相影响?!”
微服务可以解决这个问题,微服务的本质是把一块大饼分成若干块低耦合的小饼,比如一块小饼专门负责接收外部的数据,一块小饼专门负责响应前台的操作,小饼可以进一步拆分,比如负责接收外部数据的小饼可以继续分成多块负责接收不同类型数据的小饼,这样每个小饼出问题了,其它小饼还能正常对外提供服务。
DevOps
DevOps的意思就是开发和运维不再是分开的两个团队,而是你中有我,我中有你的一个团队。我们现在开发和运维已经是一个团队了,但是运维方面的知识和经验还需要持续提高。
持续交付
持续交付的意思就是在不影响用户使用服务的前提下频繁把新功能发布给用户使用,要做到这点非常非常难。我们现在两周一个版本,每次上线之后都会给不同的用户造成不同程度的影响。
容器化
容器化的好处在于运维的时候不需要再关心每个服务所使用的技术栈了,每个服务都被无差别地封装在容器里,可以被无差别地管理和维护,现在比较流行的工具是docker和k8s。
所以你也可以简单地把云原生理解为:云原生 = 微服务 + DevOps + 持续交付 + 容器化

3.6 Linux
Linux中你用过哪些指令?
1 | ps -ef #表示查看全格式的全部进程。 |
Linux三剑客
正则表达式
grep擅长查找功能,sed擅长取行和替换。awk擅长取列
grep用法
- -i 忽略字符的大小写
- -o 仅显示匹配到的字符串
- -n 显示行号
- . 匹配任意一个字符(除了换行符)
- [0-9]
1 |
sed用法
awk用法
xargs
xargs是给命令传递参数的一个过滤器,也是组合多个命令的工具
xargs默认的命令是
echo,这意味着通过管道传递给xargs的输入将会包含换行和空白,不通过xargs的处理,换行和空白将会被空格取代。之所以使用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中又有这个必要,所以就有了这个命令,例如:
2
find /sbin -perm +700 | xargs ls -lxargs一般是和管道符一起使用
你在Linux上部署过哪些应用
- 个人博客
- ftp服务器
- 搭建个人图床
- 用来写markdown笔记的Chevereto图床
- 在线的jupyter notebook
- 用docker 部署java ssm应用
apache 和 nginx比较
nginx 相对 apache 的优点:
轻量级,同样起web服务,比apache占用更少的内存及资源
抗并发,nginx处理请求是异步非阻塞的,而apache则是阻塞型的,在高并发下nginx能保持
低资源低消耗高性能
高度模块化的设计,编写模块相对简单
社区活跃,各种高性能模块出品迅速啊
apache 相对 nginx 的优点:ewrite,比nginx的rewrite强大
模块超多,基本想到的都可以找到
少bug,nginx的bug相对较多
超稳定
一般来说,需要性能的 web 服务,用 nginx 。 如果不需要性能只求稳定,那就 apache 吧。
Linux系统开机流程
https://www.linuxprobe.com/linux-boot-process-steps.html
https://www.runoob.com/linux/linux-system-boot.html
BIOS -> MBR -> 引导加载程序 -> 内核 -> init process -> login
Linux预置七种运行级别(0-6)。一般来说,0是关机,1是单用户模式(也就是维护模式),6是重启。运行级别2-5,各个发行版不太一样,对于Debian来说,都是同样的多用户模式(也就是正常模式)。
Linux系统有7个运行级别(runlevel):
- 运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
- 运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登陆
- 运行级别2:多用户状态(没有NFS)
- 运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式
- 运行级别4:系统未使用,保留
- 运行级别5:X11控制台,登陆后进入图形GUI模式
- 运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
(1)
POST 加电自检–》MBR 引导–》GRUB–》加载内核–》启动 init 进程–》读取/etc/inittab
文件,/etc/init/*.conf 文件–》使用/etc/rc.d/rc.sysinit 初始化脚本–》执行/etc/rc.d/rc
脚本(加载/etc/rc3.d/下所有脚本)–》执行/etc/rc.d/rc.local–》执行/bin/login 登录
程序(2)
查询程序运行级别:runlevel
(3)
修改运行级别:init [0123456]
Linux根目录下各个目录的用途的和含义
https://blog.csdn.net/weixin_40331034/article/details/79522923

1 | 1. /bin - 重要的二进制 (binary) 应用程序 |
free -m中的free和available有什么区别
free是真正尚未被使用的物理内存数量。
available是应用程序认为可用内存数量,available = free + buffer + cache(注:只是大概的计算方法)Linux 为了提升读写性能,会消耗一部分内存资源缓存磁盘数据,对于内核来说,buffer 和 cache 其实都属于已经被使用的内存。但当应用程序申请内存时,如果 free 内存不够,内核就会回收 buffer 和 cache 的内存来满足应用程序的请求。这就是稍后要说明的 buffer 和 cache。
正则表达式
负载均衡原理以及常见的负载均衡算法
原理
https://blog.csdn.net/okiwilldoit/article/details/81738782
加权轮询
随机法
轮询法
3.7 存储
RAID存储
https://blog.csdn.net/ensp1/article/details/81318135
RAID0
RAID0 是一种简单的、无数据校验的数据条带化技术。实际上不是一种真正的 RAID ,因为它并不提供任何形式的冗余策略。 RAID0 将所在磁盘条带化后组成大容量的存储空间(如图 2 所示),将数据分散存储在所有磁盘中,以独立访问方式实现多块磁盘的并读访问。由于可以并发执行 I/O 操作,总线带宽得到充分利用。再加上不需要进行数据校验,RAID0 的性能在所有 RAID 等级中是最高的。理论上讲,一个由 n 块磁盘组成的 RAID0 ,它的读写性能是单个磁盘性能的 n 倍,但由于总线带宽等多种因素的限制,实际的性能提升低于理论值。
RAID0 具有低成本、高读写性能、 100% 的高存储空间利用率等优点,但是它不提供数据冗余保护,一旦数据损坏,将无法恢复。 因此, RAID0 一般适用于对性能要求严格但对数据安全性和可靠性不高的应用,如视频、音频存储、临时数据缓存空间等。

什么是块存储、对象存储和文件存储
什么是DAS、SAN、NAS
DAS(Direct-attached Storage) 直连存储
直连式存储与服务器主机之间的连接通常采用 SCSI 连接 , SCSI 通道 是 IO 瓶颈 ; 服务器主机 SCSI ID 资源有限,能够建立的 SCSI 通道连接有限。无论直连式存储还是服务器主机的扩展,从一台服务器扩展为多台服务器组成的群集 (Cluster) ,或 存储阵列 容量的扩展,都会造成业务系统的停机,NAS(Network Attached Storage) 网络附加存储——是一个网络上的文件系统
存储设备通过标准的网络拓扑结构 ( 以太网 ) 添加到一群计算机上。应用:文档图片电影共享,云存储。 NAS 即插即用,支持多平台。
NAS 有一关键问题,即备份过程中的带宽消耗, NAS 仍使用网络进行备份和恢复。 NAS 的一个缺点是它将存储事务由并行 SCSI 连接转移到网络上,也就是说 LAN 除了必须处理正常的最终用户传输流外,还必须处理包括备份操作的存储磁盘请求。
NAS 需要服务器自己搜索它的硬盘**SAN(**Storage Area Network) 存储区域网络——是一个网络上的磁盘
通过光纤通道交换机连接存储阵列和服务器主机,最后成为一个专用存储网络。 SAN 提供了一种与现有 LAN 连接的简易方法,并且通过同一物理通道支持广泛使用的 SCSI 和 IP 协议。 SAN 允许企业独立地增加它们的存储容量。 SAN 的结构允许任何服务器连接到任何存储阵列,这样不管数据放在哪里,服务器都可以直接存取所需的数据。因为采用了光纤接口, SAN 还具有更高的带宽。
什么是VSAN?
什么是Ceph?
3.8 计算机网络
三次握手和四次挥手
为什么要进行三次握手,而不是两次或者四次握手
首先TCP是全双工的,也就是客户端和服务器端可以同时进行通讯,同时也需要确保传输的可靠性,如果进行两次握手的话,仅仅是客户端知道服务器端可以进行消息的收发,而服务器端仅仅知道客户端可以发送,是否接收到信息是不知道的,因此需要多加一次握手过程,来让服务器知道客户算具有发送和接受消息的能力。因此三次握手就足够进行消息通信了,没有必要进行四次握手。
三次握手

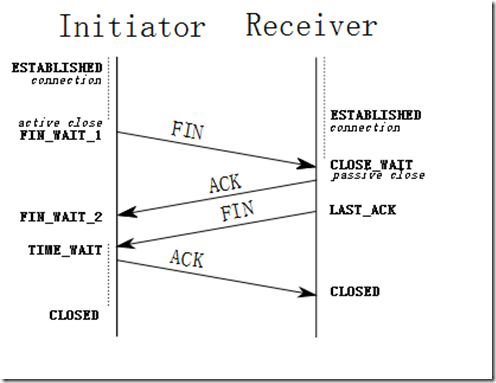
四次挥手
①客户端想要释放连接,向服务器端发送一段TCP报文,其中:标记位为FIN,表示“请求释放连接“
②服务器端接收到从客户端发出的TCP报文之后,确认了客户端想要释放连接,随后服务器端结束ESTABLISHED阶段,进入CLOSE-WAIT阶段(半关闭状态)并返回一段TCP报文,其中:标记位为ACK,表示“接收到客户端发送的释放连接的请求”;
③服务器端自从发出ACK确认报文之后,经过CLOSED-WAIT阶段,做好了释放服务器端到客户端方向上的连接准备,再次向客户端发出一段TCP报文,其中:标记位为FIN,ACK,表示“已经准备好释放连接了”。注意:这里的ACK并不是确认收到服务器端报文的确认报文。
④客户端收到从服务器端发出的TCP报文,确认了服务器端已做好释放连接的准备,结束FIN-WAIT-2阶段,进入TIME-WAIT阶段,并向服务器端发送一段报文,其中:标记位为ACK,表示“接收到服务器准备好释放连接的信号”。
OSI七层模型
物理层 :为数据端设备提供传送数据通路、传输数据
数据链路层:提供介质访问和链路管理 arp
网络层:
ip选址及路由选择 ICMP(ping命令)传输层:建立管理和维护端到端的连接 tcp/udp协议
会话层:建立、管理和维护会话
表示层:数据格式转换,数据加密(SSL)
应用层:为应用程序提供服务 http、 https、 ftp、 telnet、 smtp、 pop3、 DNS
五层协议有哪些
去掉七层协议中的会话层和表示层
物理层
数据链路层
网络层
传输层
应用层
四层网络
网络接口层 包括用于协作IP数据在已有网络介质上传输的协议。ARP,RARP
网间层
传输层
应用层
cookie和session的区别
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、可以考虑将登陆信息等重要信息存放为session,其他信息如果需要保留,可以放在cookie中。
tcp/udp的区别
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付,TCP通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
3、UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
4.每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP对系统资源要求较多,UDP对系统资源要求较少。
UDP对实施应用很有用如视频会议或者直播,但是在实际开发中直播一般还是采用的TCP。常见的直播方案都是上行采用rtmp;下行采用http-flv或者hls,底层都是TCP。利用rtmp协议可以很快搭建一套直播系统,客户端、服务器都有成熟稳定的开源实现。注意
UDP是不会对数据报文进行任何拆分和拼接操作的
TCP如何确保可靠传输的
TCP 的拥塞控制
TCP的四种拥塞控制算法: 1.慢开始 2.拥塞控制 3.快重传 4.快恢复
Get和Post请求的区别
http和https的区别
一、传输信息安全性不同
1、http协议:是超文本传输协议,信息是明文传输。如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息。
2、https协议:是具有安全性的ssl加密传输协议,为浏览器和服务器之间的通信加密,确保数据传输的安全。
二、连接方式不同1、http协议:http的连接很简单,是无状态的。
2、https协议:是由SSL(安全套接字协议)+HTTP协议构建的可进行加密传输、身份认证的网络协议。
三、端口不同
1、http协议:使用的端口是80。
2、https协议:使用的端口是443.
四、证书申请方式不同
1、http协议:免费申请。
2、https协议:需要到ca申请证书,一般免费证书很少,需要交费。
http状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求(拒绝执行请求) |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面(找不到资源) |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
http1.0 1.1 和2.0的区别
DHCP的工作原理
客户端发送广播包到DHCP服务器
DNS的工作原理
DNS 全称叫做域名解析系统
例如我们访问www.baidu.com,实际上在背后我们是访问对应web服务器的ip地址,但是对于人来说,记住ip地址要更加繁琐,因此可以用域名来方便人们记忆
ARP协议
是根据IP地址获取物理地址的一个TCP/IP协议
他是工作在数据链路层的一个协议
RARP
反向地址转换协议
使用的电脑访问不了外网,排查思路是什么?
可以来使用traceroute命令进行排查,看具体是内网不同还是上外网不通
RIP和OSPF有什么区别
rip和OSPF的学习方式
rip 适合于小型网络
OSPF 适合中大型网络
3.9 操作系统
什么是死锁?发生原因是什么?如何解决和避免产生死锁?
①多个进程争夺一个资源导致陷入一个互相等待的僵局。
②
③银行家算法
进程和线程的区别
一个进程可以包含多个进程
进程是
线程是
协程
1 |
3.10 数据库
什么是数据连接池
连接池是一种常用的技术,谈到他的话要从TCP讲起。假如我们的服务和数据库没有部署在同一台服务器上,那么我们每次查询数据库的过程中,都要先进行TCP的三次握手,然后再进行数据的访问操作,结束了之后再进行TCP的四次挥手。在建立连接上花费了很多的时间,这样下来数据的查询的效率就非常低了。
不使用数据库连接池的步骤:
- TCP建立连接的三次握手
- MySQL认证的三次握手
- 真正的SQL执行
- MySQL的关闭
- TCP的四次握手关闭
可以看到,为了执行一条SQL,却多了非常多我们不关心的网络交互。
使用数据库连接池的步骤:
第一次访问的时候,需要建立连接。 但是之后的访问,均会复用之前创建的连接,直接执行SQL语句。
为什么要用连接池
为了解决上述问题,我们就需要维护一些长链接,这样就不用每次都去建立连接,毕竟建立连接除了占用时间,还需要一些其他的系统资源。另外的好处,连接池让我们更加容易地管理,一方面是可以避免数据库资源都被某几个API占据,另一方面也可以避免资源泄露。
连接池有什么好处
①资源重用 (连接复用)
由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,增进了系统环境的平稳性(减少内存碎片以级数据库临时进程、线程的数量)
②更快的系统响应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池内备用。此时连接池的初始化操作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
③新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接技术。
④统一的连接管理,避免数据库连接泄露
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用的连接,从而避免了常规数据库连接操作中可能出现的资源泄露
为什么要用数据库索引,怎么用?如何创建?
索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
create index xxx on
MySQL有哪些索引
1.普通索引
2.唯一索引
3.主键索引
4.组合索引
5.全文索引
数据库冷热备份
如何优化数据库
SQL的聚合函数
count()
avg()
sum()
max()
min()
一条SQL语句的执行过程
数据库事务的ACID
一个事务本质上有四个特点ACID:
- Atomicity原子性
- Consistency一致性
- Isolation 隔离性
- Durability 耐久性
原子性
原子性任务是一个独立的操作单元,是一种要么全部是,要么全部不是的原子单位性的操作。
一致性
一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
一致性有下面特点:
- 如果一个操作触发辅助操作(级联,触发器),这些也必须成功,否则交易失败。
- 如果系统是由多个节点组成,一致性规定所有的变化必须传播到所有节点(多主复制)。如果从站节点是异步更新,那么我们打破一致性规则,系统成为“最终一致性”。
- 一个事务是数据状态的切换,因此,如果事务是并发多个,系统也必须如同串行事务一样操作。
在现实中,事务系统遭遇并发请求时,这种串行化是有成本的, Amdahl法则描述如下:它是描述序列串行执行和并发之间的关系。
“一个程序在并行计算情况下使用多个处理器所能提升的速度是由这个程序中串行执行部分的时间决定的。”
大多数数据库管理系统选择(默认情况下)是放宽一致性,以达到更好的并发性。
隔离性
事务是并发控制机制,他们交错使用时也能提供一致性。隔离让我们隐藏来自外部世界未提交的状态变化,一个失败的事务不应该破坏系统的状态。隔离是通过用悲观或乐观锁机制实现的。
耐久性
一个成功的事务将永久性地改变系统的状态,所以在它结束之前,所有导致状态的变化都记录在一个持久的事务日志中。如果我们的系统突然受到系统崩溃或断电,那么所有未完成已提交的事务可能会重演。
3.11 设计模式
请说一下你对“高内聚低耦合”的理解
高内聚:修改一个模块的时候不会对其他的模块造成影响
低耦合:模块之间的关联尽量减少
你开发的程序里面你用过哪些设计模式
简单工厂模式
工厂模式
抽象工厂模式
单例模式
职责链模式
常见的设计模式有哪些?
简单工厂模式
工厂模式
抽象工厂模式
单例模式
职责链模式
适配器模式
3.12 前端
Java和js的区别
首先,Java和JavaScript是没有一点关系的。
其次就是Java是用来写后端的语言,js是用来写前端的语言。
Vue生命周期
3.13 安全
什么是DDOS攻击
3.14 Git
git merge和rebase的区别
这两条指令都是用来合并分支的,
分支
3.15 云计算方向
谈谈你对IaaS、SaaS、PAAS的理解
四、综合素质
你自己的优缺点怎么样
举个例子,你可以说:我之前工作容易心急,一直都是非常忙碌的状态,分不清重要和紧急的事,总想把所有事情都尽快解决,很容易慌乱。后来我看了《高效能人士的七个习惯》,学习了事情应该分轻重缓急,理解了什么是重要紧急、重要不紧急等等,慢慢找到了做事的正确方法,让我受益匪浅。
在校期间参加过什么活动、社团等
业余时间有什么兴趣爱好?
四、最后提问环节
公司对我这个职位的期望是什么?
这个职位在公司内部未来的一个发展方向是什么样子的?
公司对于新人有一个什么样的培训体系?
公司的技术团队大有多少人?
为了胜任这个岗位我还需要去学习哪些技术?
所在团队人员分工情况介绍。
这个职位未来几年的职业发展是怎样的?
+
为了胜任这个岗位我还需要学习哪些技术知识?
- vue
- Flask
- OpenStack
- ceph
- Django
- Docker
对于实习生或者应届生技能上的要求?
- 前后端
刚才问的那个技术问题某个细节我还不太明白,能解释下吗?
五、总结
六、参考Reference
[1] 菜鸟教程 https://www.runoob.com/



